what to know
- Enter the website URL (domain or specific page) into the Wayback Machine search bar.
- View timestamped calendar results showing how often the site was captured over the years.
- Explore cached sites by hovering over the timestamp and selecting a specific date and time.
The Internet is constantly evolving. The website and its information disappear, replaced by a new one. The Wayback Machine is a digital time capsule that saves snapshots of your website over the years. This article will show you how to use this valuable historical resource.
The Wayback Machine search engine is the first place you should look for archived web pages and websites. The search box is also prominently featured on the Internet Archive's home page. Click on the Wayback Machine logo to go to its home page.
The Wayback Machine search field works like any other search engine. The site ranks search results based on how often the site is saved and the number of relevant links each home page has.
In the Wayback Machine's search bar, enter the URL of the website that interests you. You can use a domain URL (such as www.example.com) or a specific page on your website.
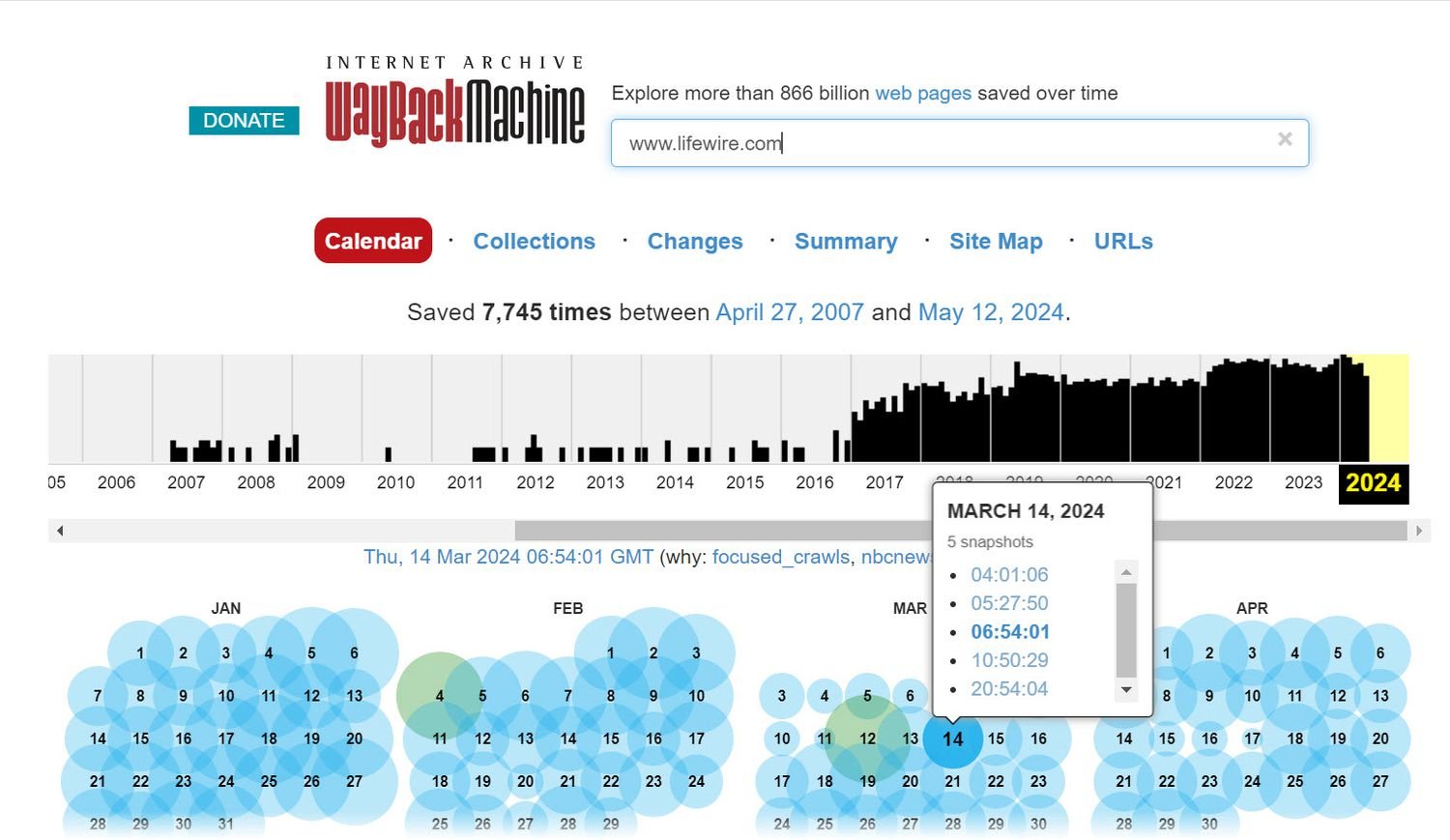
The results are displayed as a calendar with the year at the top and a monthly view for that specific year.
notes:
The calendar view shows the number of times the Wayback Machine has checked the site; it does not show the number of updates the page has received.
Hover over any date to see a snapshot of that day. Select the time for the snapshot. The size of the circle is proportional to the number of snapshots for that date. You may also see different colored circles:
- Blue : The crawler has no problems retrieving the page.
- Green : The crawler discovered the redirect.
- Orange : The crawler has problems on the client side, such as a 404 (page not found) error.
- Red : The crawler found a server error, such as a 502 (Bad Gateway) error.
For best results, click only blue links.
Browse the site on a snapshot. Since you are not viewing the live page, some links may not work. Additionally, the search functionality on the archived site will not work as well as on the live site.
notes:
You cannot download snapshots directly from the Wayback Machine; their terms of use do not allow this.
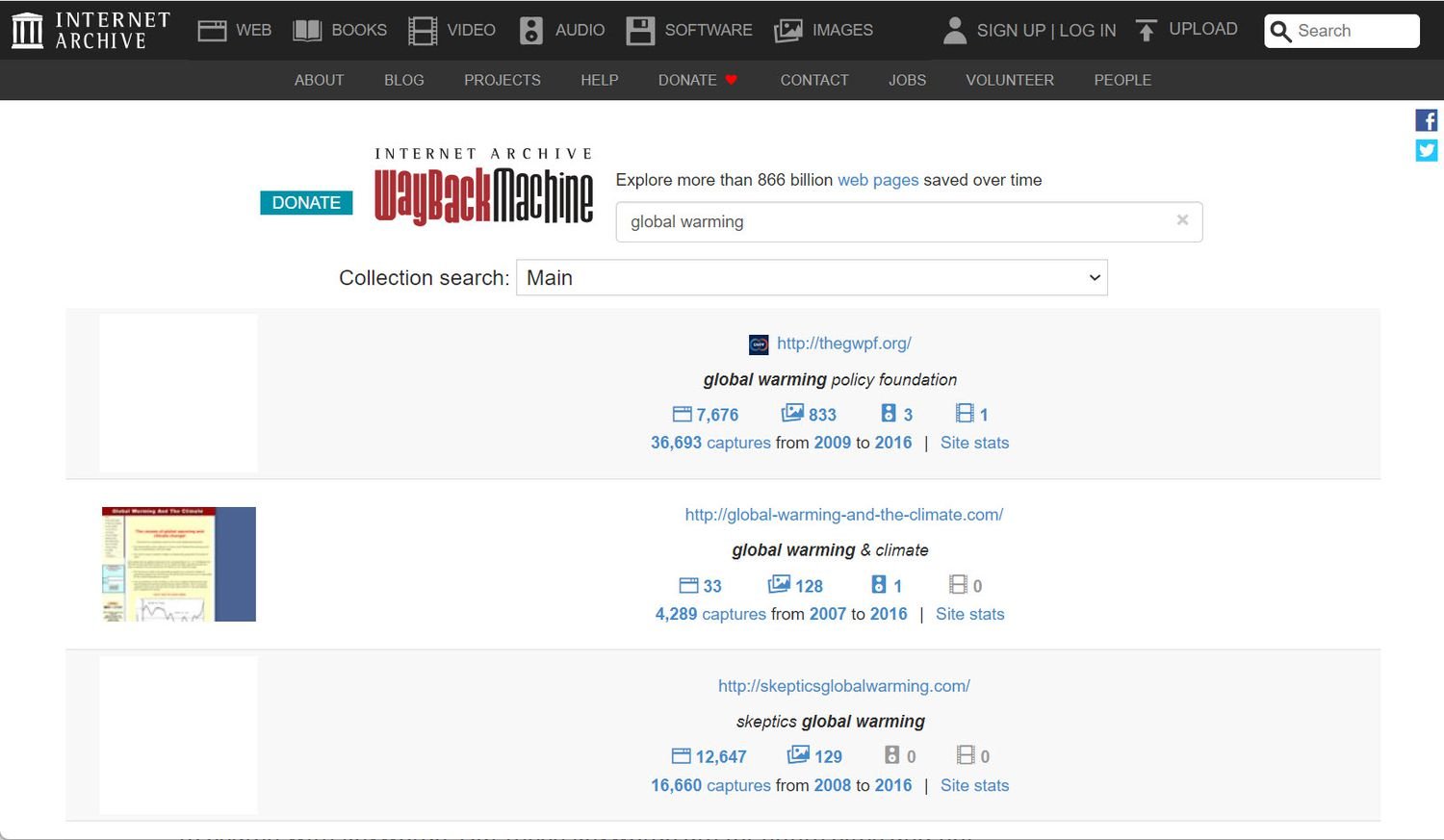
Although the Wayback Machine only works with URLs, its ability to search using keywords is limited. However, these keywords apply to the entire website, rather than being keywords hidden within individual web pages.
For example, if you use a keyword like "global warming," you won't see every page containing that word. Instead, you'll get a website about global warming.
When you do a keyword search, you have to look at the results to find the website you're searching for. This is still a great way to discover older websites with relevant information, such as academic journals.
hint
The Wayback Machine also supports multilingual keyword searches as well as site search operators (for example, site:nytimes.com "global warming").
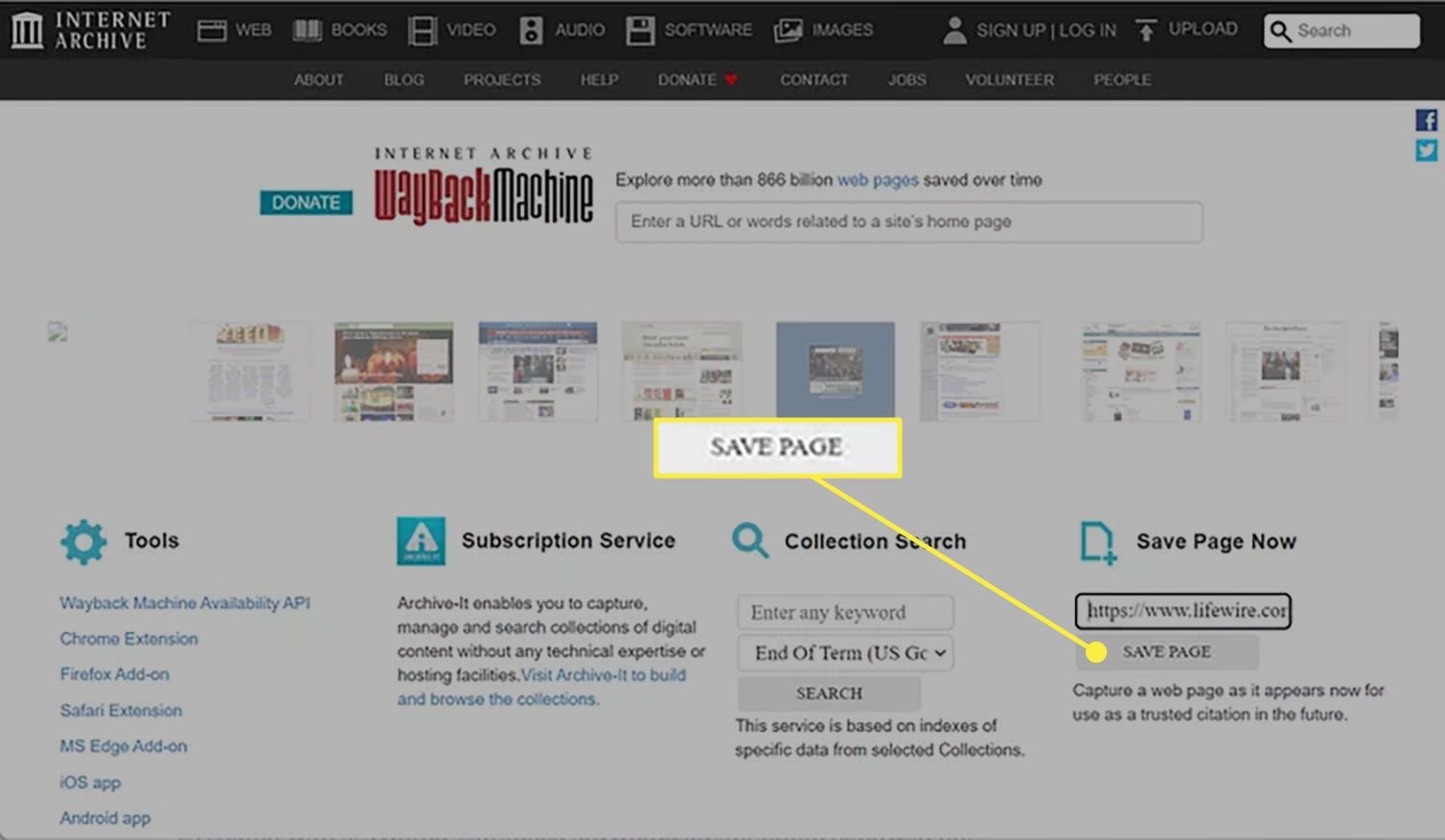
The Save Page Now feature lets you add and archive web pages to the Wayback Machine. However, you cannot yet save the entire website, only a relevant number of pages (via external links on the target page).
Go to the Wayback Machine home page.
Enter the URL of the page you want to archive in the "Save page now" field.
If you don't see this field, make sure you're visiting web.archive.org and not just archive.org .
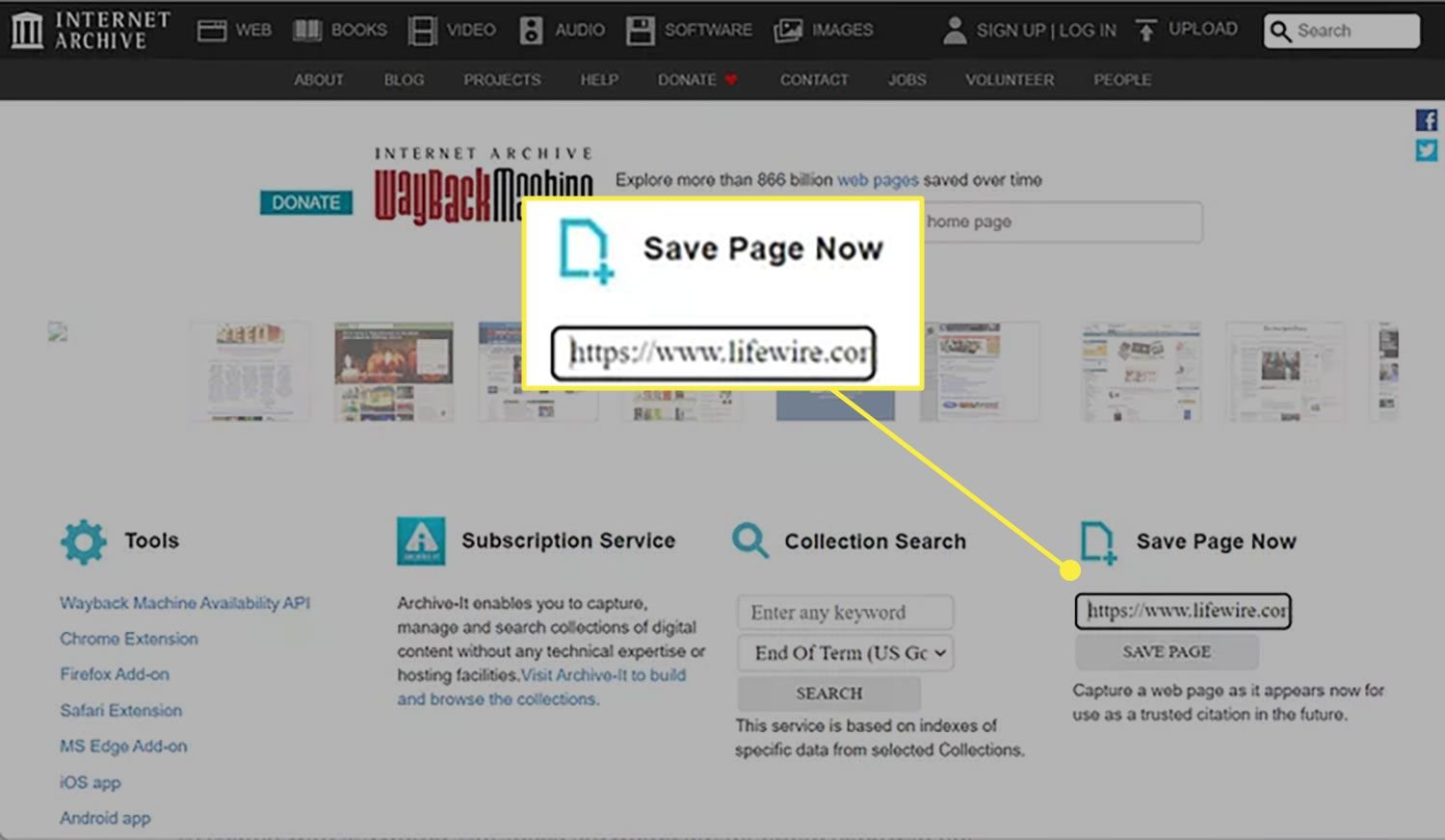
Select Save Page .
Signing up and logging in with a free account provides more options, such as saving page screenshots, keeping a personal web archive, emailing search results to yourself, and using WACZ files.
hint
If you use Wayback Machine regularly, consider their Chrome extension. This extension is an indirect way of "searching" the Wayback Machine, as you can automatically view a site's archived pages by clicking on it. If the web page you are trying to access does not exist or displays a 404 Not Found error, this is a useful way to view cached pages. Check the extension's settings for extra features. Extensions and add-ons are also available for Safari, Edge, and Firefox.
The Wayback Machine is part of the Internet Archive, a nonprofit organization founded in 1996 by Brewster Kahle and Bruce Gilliat to preserve the World Wide Web and create accessible Search public libraries for digital assets. Since then, the Internet Archive has grown to include millions of free books, movies, software, music, art, video games, and more.
notes:
Other open resources are also available, including the Open Library (a library of digital books) and the NASA Image Archive (a collection of images from the NASA Archives).
Wayback Machine was the first service made available to the public in 2001. It captures and indexes snapshots of web pages, allowing users to see what the website looked like at different points in time. This tool is invaluable for researchers, historians, and anyone interested in the development of the Internet or recovering lost content.
The Wayback Machine currently has a searchable index of 866 billion web pages. You can think of it as a stealth search engine that finds cached versions of websites that no longer exist.
