 You can now edit some DALL-E images.
You can now edit some DALL-E images.No doubt you've noticed the proliferation of artificial intelligence art generators in the last year or so: super-intelligent engines that can generate images that look just like real photos, or artwork created by real people. Over time, they have become more powerful and added more and more features - you can even find AI art tools in Microsoft Paint now.
A new feature of the DALL-E AI image model, available to ChatGPT Plus members who pay $20 per month, is the ability to edit parts of an image just like you do in Photoshop: you no longer have to regenerate entirely new Image just because you want to change one element of it - you show DALL-E the part of the image you want to adjust, give it some new instructions, and leave everything else alone.
It overcomes one of the important limitations of AI art, which is that every image (and video) is completely unique and different, even if you use the same prompt. This makes it difficult to achieve consistency between images, or to fine-tune an idea. However, these AI art creators, based on so-called diffusion models, still have many limitations to overcome – as we will show you here.
Edit images in ChatGPT
If you're a ChatGPT Plus subscriber, you can load the app on the web or your mobile device and request any images you like: cartoon dog detectives solving crimes in a cyberpunk environment, rolling hills and lonely landscapes. Figures in the middle distance and storm clouds gathering overhead, or something. In a few seconds, you have your photo.
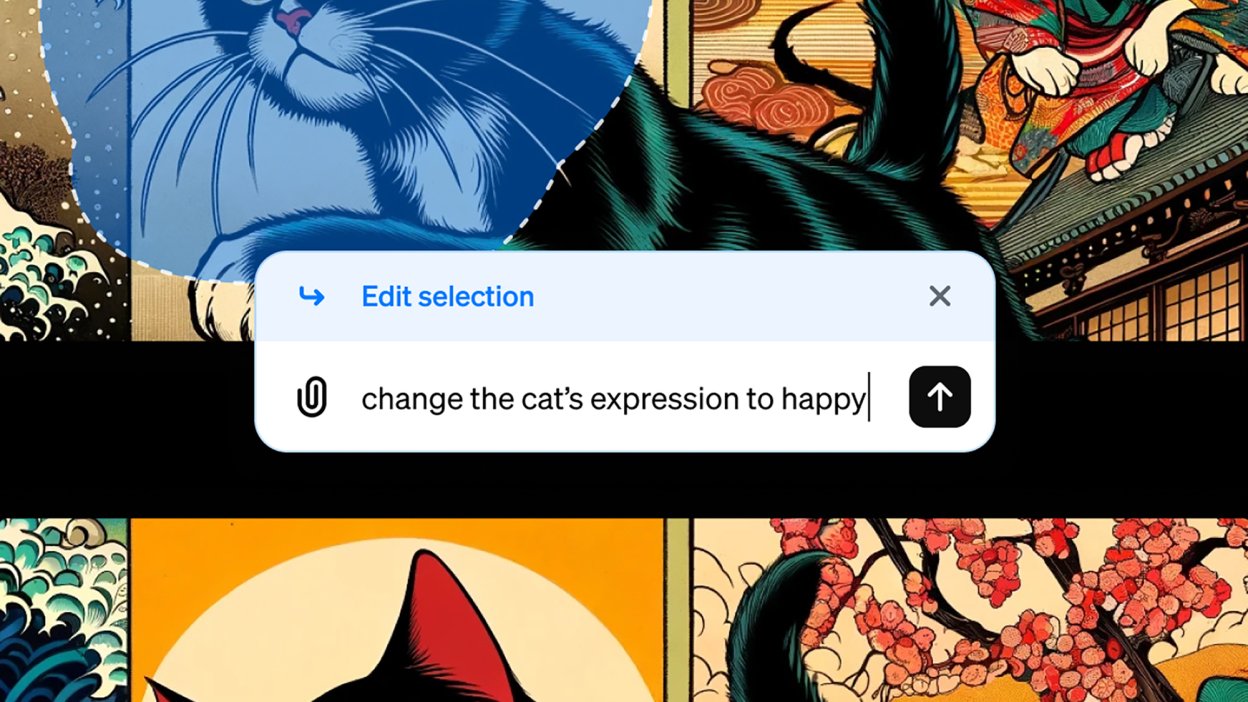
To edit the picture, you can now click on the resulting image and then click the Select button in the upper right corner (it looks like a pen drawing a line). You can then use the slider in the upper left corner to adjust the size of the selection tool and paint over the parts of the image you want to change.
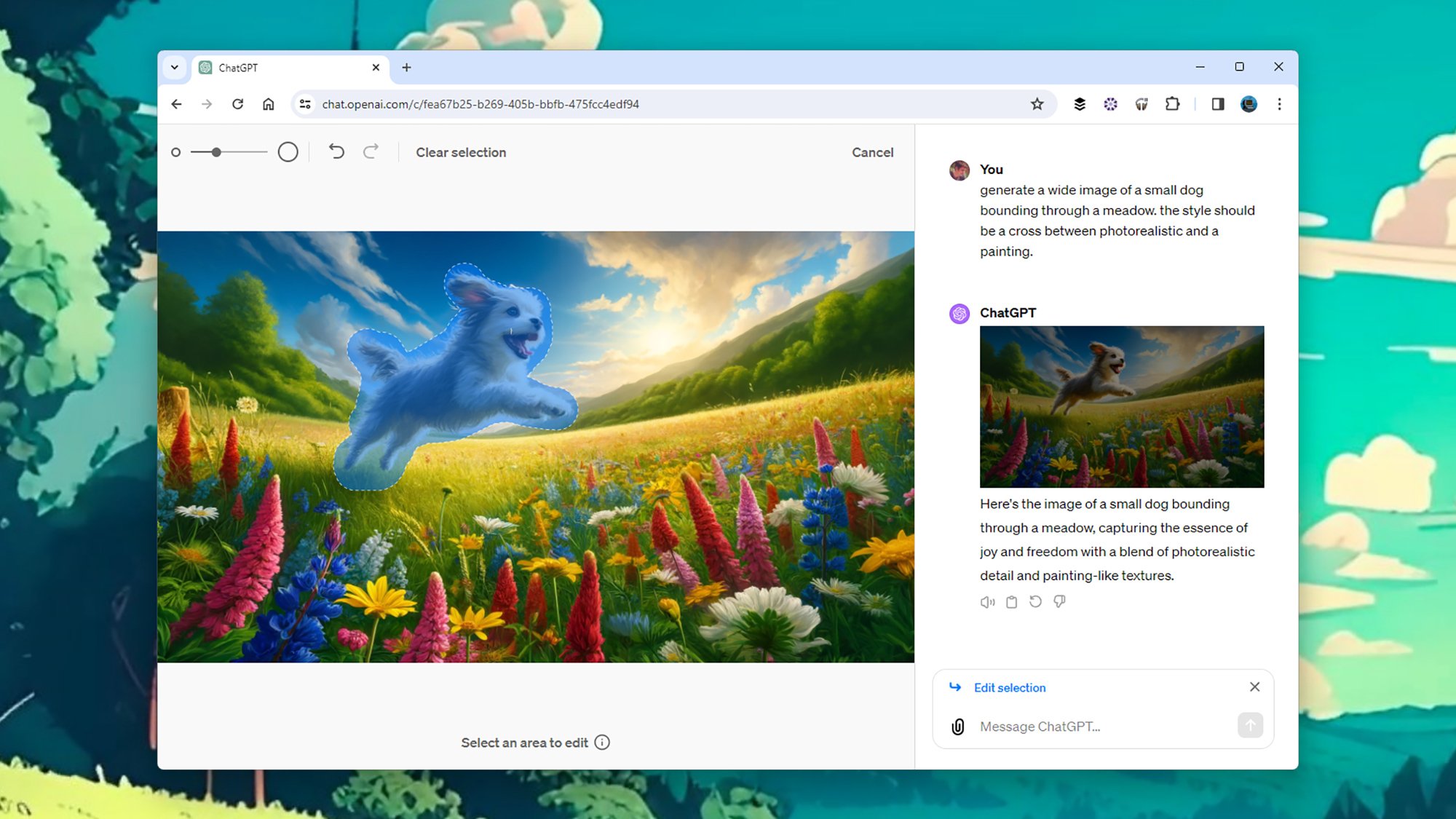
This is a great step forward: you can keep part of the image unchanged and just refresh the selection. Previously, if you sent a follow-up prompt to change a specific part of the image, the entire image would be regenerated and would likely look significantly different from the original image.
When you make your selection, you'll be prompted to enter a new description that will only apply to the highlighted portion of the image. As always when using these AI art tools, the more specific your requests are, the better: you might ask for a person to look happier (or less happy), or for a building to be a different color. Your requested changes will then be applied.

Based on my experiments, ChatGPT and DALL-E appear to deploy the same type of AI tricks we've seen in apps like Google's Magic Eraser: intelligently filling in the background based on existing information in the scene, while trying to keep everything in outside the scene. The selection remains unchanged.
It's not the most advanced selection tool, and I did notice inconsistencies in borders and object edges - perhaps to be expected given the amount of control you get when selecting. A lot of the time, the editing feature works pretty well, although it's not reliable every time, which is certainly something OpenAI hopes to improve in the future.
Where are the limits of artificial intelligence art?
I tried new editing tools to accomplish various techniques. It did a good job of changing the color and position of a dog on the grass, but it didn't do a good job of reducing the size of a giant standing on a castle wall - the man just disappeared into the blur of wall fragments, suggesting artificial Smart is trying to paint a picture around him, but without much success.
In the cyberpunk scene, I asked for a car to park and no car showed up. In another castle scene, I asked to turn a flying dragon around so it was facing the other direction, change from green to red, and add fire coming from its mouth. After a period of processing, ChatGPT removed the dragon completely.

The feature is still new, and OpenAI isn't yet claiming it can replace human image editing — because it clearly can't. It will improve, but these bugs help illustrate where the challenges lie for certain types of AI-generated art.
What DALL-E and similar models are very good at is knowing how to arrange pixels to give a good approximation of a castle (for example) based on the millions(?) castles they have been trained on. However, the AI doesn't know what a castle is: it doesn't understand geometry or physical space, which is why my castle has turrets that come out of nowhere. You'll notice this in a lot of AI-generated art involving buildings, furniture, or any object that isn't rendered correctly.

Essentially, these models are probabilistic machines, but don't understand (yet) what they actually display: that's why in many OpenAI Sora videos, people disappear without a trace, because the AI arranges the pixels very cleverly, Instead of stalking people. You may have also read about artificial intelligence efforts to create photos of interracial couples because, based on image training data, same-race couples are more likely.
Another quirk noticed recently is the inability of these AI art generators to create pure white backgrounds. These are incredibly smart tools in many ways, but they don't "think" like you or me, nor do they understand what they're doing like a human artist does - it's important to accept that when you use Please keep them in mind.
